Наша команда анализа защищенности давно занимается поиском уязвимостей в самых разнообразных системах, от биометрического сканера до головного юнита Mercedes-Benz. Но в жизни каждого исследователя безопасности прошивок однажды наступает момент, когда он или она сталкивается с новым (или не особо известным) микроконтроллером или свежей процессорной архитектурой с кастомными расширениями.
В последнее время такие моменты наступают все чаще — за прошедшие несколько лет рынок наполнился огромным количеством новых чипов из Поднебесной, со своими собственными расширениями и реализациями ядер. И вот не так давно на анализ нашим исследователям попало устройство c таким чипом на базе RISC-V, c базовым набором инструкций RV32I и расширением P (причем еще и не последней версии), добавляющим короткие SIMD-операции (Packed-SIMD Instructions).
То, что наши эксперты видели его впервые — абсолютно нормально. Но, по всей видимости, его впервые видел и IDA Pro — инструмент, которым пользуются наши исследователи. Поэтому нам пришлось не только изучить ранний черновик расширения P (оно же Packed-SIMD Extension), но также реализовать для IDA Pro поддержку ряда инструкций из этого расширения и произвести лифтинг, то есть трансляцию инструкций в промежуточное представление или язык, понятные декомпилятору. Именно этим опытом мы и поделимся в данной статье.
Но прежде чем переходить к описанию решения, стоит понять, с чем мы имеем дело. Поэтому для начала познакомимся с архитектурой RISC-V.
Особенности формата инструкций RISC-V#
В базовом наборе инструкций архитектуры RV32I четыре формата: R, I, S, U. Информацию о каждом из них, а также о других можно найти в руководстве The RISC-V Instruction Set Manual Volume I: Unprivileged ISA.
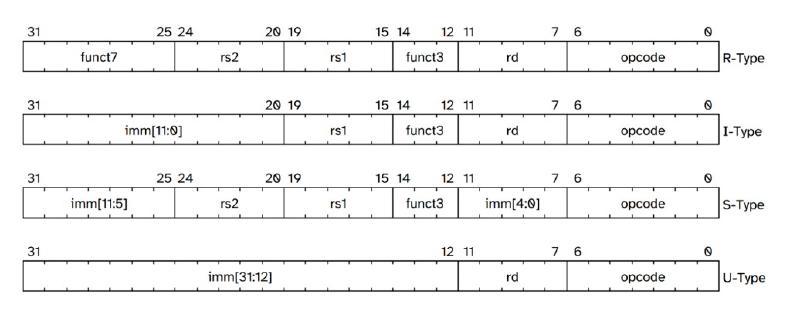
Внимательный читатель сразу заметит особенности кодировки инструкций: опкоды и регистры имеют фиксированное расположение. Это сделано неслучайно, при подобном исполнении устройство декодера инструкций сильно облегчается и упрощается. Кроме того, декодер инструкций RISC-V построен на базе таблиц, что благотворно влияет на процесс разбора инструкций процессором.
Взгляд на декодер#
Точкой входа процесса декодирования является поле opcode, которое занимает младшие 7 битов 32-битной инструкции, — inst[6:0]. Декодер — табличный, его схема представлена ниже.
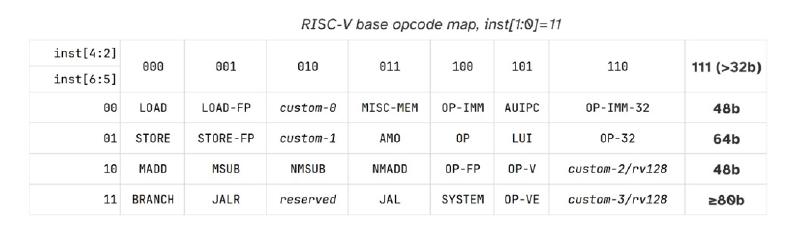
У 32-битных и более широких инструкций младшие 2 бита всегда имеют значение 11, остальные 5 битов кодируют индекс внутри таблицы. В каждой ячейке таблицы может быть либо указатель на другую таблицу, либо декодер конечной инструкции, либо ничего (как водится — Reserved).
P Extension#
С основами декода разобрались, осталось понять, где обитают инструкции из P Extension и как их парсить (декодировать). Для этого необходимо обратиться к черновику расширения, который можно найти в репозитории riscv/riscv-p-spec на GitHub. В нашем случае требуется одна из первых публичных версий — 0.5, поэтому запасаемся терпением, пуэром и поворачиваем время вспять — отматываем историю коммитов назад.
Версия 0.5, как и ряд последующих, примечательна тем, что использует значение 0x7F или 0b1111111 для опкода. В этом и был нюанс, который в итоге доставил нам немало хлопот. Дело в том, что данное значение используется для кодирования инструкций 80+ бит. Декодер тупой как пробка. Если не внести в его конструкцию изменения, он так и будет вычитывать по 80+ бит, что конкретно в этом случае не соответствует действительности — инструкции данного расширения имеют длину 32 бита. Ибо в ранней версии, с которой мы столкнулись, использовалось именно это значение для опкода — 0x7F (хотя не должно было, потому что это ломает «базу» декодера, идет вразрез с оригинальной спецификацией ISA).
Более подробно об устройстве кодировки длин инструкций можно прочитать в соответствующем разделе документации. А кратко — в таблице ниже.

Лирическое отступление: знакомство с этим расширением началось с недекодируемых инструкций в ассемблерных листингах IDA Pro, а опкод 0x7F только подливал масла в огонь и сбивал с толку. Определение конечного расширения и его точной версии вылилось в отдельный квест, интуиция подсказывала, что это инструкции формата R-Type, а впрочем, это уже совсем другая история…
Добавление поддержки инструкций#
Но вернемся от теории к практике. Для исследования устройства необходимо добавить поддержку инструкций umar64, maddr32, msubr32, mulsr64, mulr64. К счастью, все они находятся в рамках одной таблицы декода, о чем сказано в главе Instruction Encoding Table черновика расширения P Extension. Открываем любимый текстовый редактор или же блокнот, вспоминаем Python и приступаем.
База и абстракции#
Как упоминалось ранее, внутри таблицы декода могут содержаться либо вложенные таблицы, либо декодеры конечных инструкций. Держим эту мысль в уме и реализуем несколько абстрактных и базовых классов:
class ITableEntry(metaclass=ABCMeta):
pass
class InstructionTable(ITableEntry):
def __init__(self,
rows: int,
cols: int,
get_row: Callable[[insn_t], int],
get_col: Callable[[insn_t], int],
*entries):
if rows * cols != len(entries):
raise ValueError(f"Rows ({rows}) and cols ({cols}) don't match entries length ({len(entries)})")
self._rows = rows
self._cols = cols
self._get_row = get_row
self._get_col = get_col
self._entries = entries
def _index(self, row: int, col: int) -> int:
return row * self._cols + col
def lookup(self, insn: insn_t) -> Optional[ITableEntry]:
row = self._get_row(insn)
col = self._get_col(insn)
idx = self._index(row, col)
entry = self._entries[idx]
return entry.lookup(insn) if isinstance(entry, InstructionTable) else entry
class ADecoder(ITableEntry):
@staticmethod
def _b2m(bits: int) -> int:
return (1 << bits) - 1
@classmethod
def _bits(cls, value: int, hi: int, lo: int) -> int:
return (value >> lo) & cls._b2m(hi - lo + 1)
@classmethod
def decode(cls, insn: insn_t) -> bool:
...Класс ITableEntry описывает сущность таблицы декода; дочерний класс InstructionTable — саму таблицу, а ADecoder — базовый класс, от которого наследуются другие, в том числе и декодеры конечных инструкций.
Чуть подробнее остановимся на классе InstructionTable: аргументы rows и cols определяют геометрию таблицы декодирования (согласно описанию), get_row и get_col — методы, которые извлекают индексы в рамках таблицы из инструкции, entries — элементы таблицы.
База R-Type#
Так как интересующие нас инструкции имеют формат R-Type, создадим для этого отдельный вспомогательный класс.
class RTypeDecoder(ADecoder, ITableEntry):
_itype: ClassVar[int] = -1
@classmethod
def decode(cls, insn: insn_t) -> bool:
opcode = get_bytes(insn.ea, 1)[0]
# GE80B encoding is used for v0.5.x
if opcode & 0x7F != 0x7F:
print(f"Invalid opcode {opcode & 0x7F}")
return False
data = int.from_bytes(get_bytes(insn.ea, 4), byteorder="little")
insn.size = 4
insn.Op1.type = o_reg
insn.Op1.reg = cls._bits(data, 11, 7) # Rd
insn.Op2.type = o_reg
insn.Op2.reg = cls._bits(data, 19, 15) # Rs1
insn.Op3.type = o_reg
insn.Op3.reg = cls._bits(data, 24, 20) # Rs2
insn.itype = cls._itype
return TrueНеобходимо переопределить поведение метода decode, оно будет общим для всех инструкций. Алгоритм следующий:
проверяем, что опкод соответствует нужному значению;
вычитываем инструкцию целиком (32 бита или 4 байта);
заполняем информацию об аргументах — 3 регистра и их номера.
Наш квинтет#
Завершающий маневр декодирования инструкций — указание конкретных внутренних идентификаторов. Для этого создаем перечисление идентификаторов инструкций (здесь их получается пять) и конечные классы, в которых доопределяется поведение метода decode.
class PExtension:
maddr32 = CUSTOM_INSN_ITYPE
msubr32 = CUSTOM_INSN_ITYPE + 1
mulr64 = CUSTOM_INSN_ITYPE + 2
umar64 = CUSTOM_INSN_ITYPE + 3
mulsr64 = CUSTOM_INSN_ITYPE + 4
name_mapping = {
maddr32: "maddr32",
msubr32: "msubr32",
mulr64: "mulr64",
umar64: "umar64",
mulsr64: "mulsr64",
}
@classmethod
def values(cls) -> Set[int]:
return set(list(cls.name_mapping.keys()))
class Maddr32(RTypeDecoder):
_itype: ClassVar[int] = PExtension.maddr32
class Msubr32(RTypeDecoder):
_itype: ClassVar[int] = PExtension.msubr32
class Mulr64(RTypeDecoder):
_itype: ClassVar[int] = PExtension.mulr64
@classmethod
def decode(cls, insn: insn_t) -> bool:
res = super().decode(insn)
if not res:
return False
insn.Op1.reg = insn.Op1.reg & ~1 # Rd - pair of registers
return True
class Umar64(RTypeDecoder):
_itype: ClassVar[int] = PExtension.umar64
class Mulsr64(RTypeDecoder):
_itype: ClassVar[int] = PExtension.mulsr64Таблицы декода#
Финальный штрих — таблицы декода, их всего 3 штуки:
def b2m(bits: int) -> int:
return (1 << bits) - 1
def bits(value: int, hi: int, lo: int) -> int:
return (value >> lo) & b2m(hi - lo + 1)
def insn_data(insn: insn_t, length: int) -> int:
return int.from_bytes(get_bytes(insn.ea, length), byteorder="little")
p_funct3_001 = InstructionTable(
16, 8,
lambda insn: bits(insn_data(insn, 4), 31, 28),
lambda insn: bits(insn_data(insn, 4), 27, 25),
None, None, None, None, None, None, None, None,
None, None, None, None, None, None, None, None,
None, None, None, None, None, None, None, None,
None, None, None, None, None, None, None, None,
None, None, None, None, None, None, None, None,
None, None, None, None, None, None, None, None,
None, None, None, None, None, None, None, None,
None, None, None, None, None, None, None, None,
None, None, None, None, None, None, None, None,
None, None, None, None, None, None, None, None,
None, None, Umar64, None, None, None, None, None,
None, None, None, None, None, None, None, None,
None, None, Maddr32, Msubr32, None, None, None, None,
None, None, None, None, None, None, None, None,
Mulsr64, None, None, None, None, None, None, None,
Mulr64, None, None, None, None, None, None, None,
)
ge80b_table = InstructionTable(
1, 8,
lambda insn: 0,
lambda insn: bits(insn_data(insn, 4), 14, 12),
None, p_funct3_001, None, None, None, None, None, None,
)
rv_table = InstructionTable(
4, 8,
lambda insn: bits(insn_data(insn, 4), 6, 5),
lambda insn: bits(insn_data(insn, 4), 4, 2),
None, None, None, None, None, None, None, None,
None, None, None, None, None, None, None, None,
None, None, None, None, None, None, None, None,
None, None, None, None, None, None, None, ge80b_table,
)Пробежимся по таблицам: rv_table — базовая таблица RISC-V, ge80b_table — таблица декода инструкций с опкодом 0x7F или 0b1111111, p_funct3_001 — таблица декода P Extension с funct3 = 001 в соответствии с описанием, из этой таблицы выход на декодеры конечных инструкций.
Интегрируем в IDA Pro#
На этом описание логики декода заканчивается, остается лишь «подружить» наше творчество с IDA Pro. Для этого наследуем класс от IDP_Hooks и переопределяем в нем поведение методов анализа инструкций (ev_ana_insn) и отображения мнемоник и операндов (ev_out_mnem, ev_out_operand).
class PExtensionIdpHook(IDP_Hooks):
def __init__(self):
IDP_Hooks.__init__(self)
@staticmethod
def _b2m(bits: int) -> int:
return (1 << bits) - 1
@classmethod
def _bits(cls, value: int, hi: int, lo: int) -> int:
return (value >> lo) & cls._b2m(hi - lo + 1)
def _decode(self, insn: insn_t) -> "bool":
opcode = get_bytes(insn.ea, 1)[0]
if opcode & 0x7F != 0x7F:
return False
entry: ADecoder = rv_table.lookup(insn)
if entry is None:
return False
return entry.decode(insn)
def ev_ana_insn(self, out: "insn_t *") -> "bool":
return self._decode(out)
def ev_out_mnem(self, outctx: "outctx_t *") -> "int":
typ = outctx.insn.itype
if typ >= CUSTOM_INSN_ITYPE and typ in PExtension.name_mapping:
mnem = PExtension.name_mapping[typ]
outctx.out_tagon(COLOR_INSN)
outctx.out_line(mnem)
outctx.out_tagoff(COLOR_INSN)
width = max(1, 16 - len(mnem))
outctx.out_line(" " * width)
return 1
return 0
def ev_out_operand(self, outctx: "outctx_t *", op: "op_t const *") -> "bool":
insn = outctx.insn
if insn.itype in PExtension.values():
if op.type == o_displ:
outctx.out_value(op, OOF_ADDR)
outctx.out_register(ph_get_regnames()[op.reg])
return True
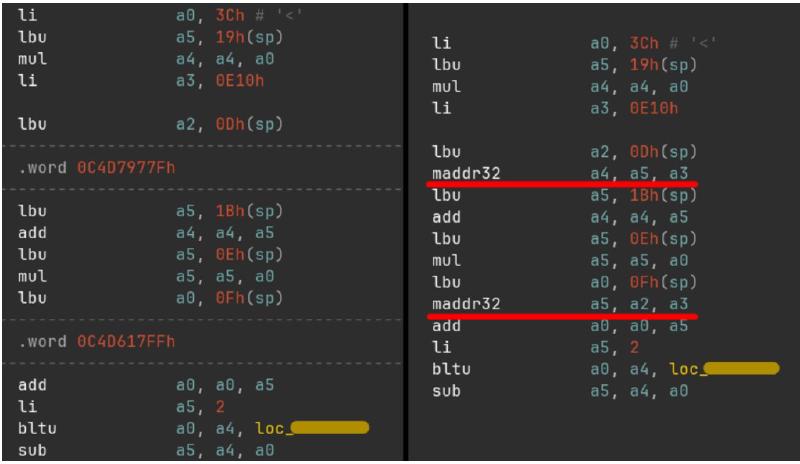
return FalseСравнение до и после применения нашего расширения представлено ниже.
Добавление поддержки декомпилятора#
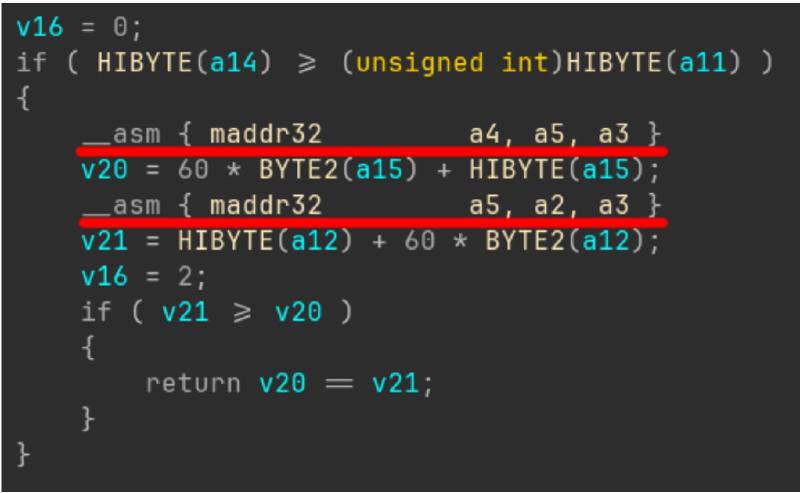
Поддержку инструкций добавили — но работа еще не закончена: выхлоп декомпилятора оставляет желать лучшего. На местах декодированных инструкций подставились ассемблерные вставки, а операции над регистрами и их значения никак не учитываются.
Проблема разрешается за счет разработки лифтера (Lifter). Вынесем поведение в отдельный класс (наследуя от microcode_filter_t), в методах которого опишем процедуру лифтинга с использованием микрокода декомпилятора Hex-Rays. Информацию по микрокоду можно почерпнуть здесь, а также из SDK декомпилятора. Для отладки подобных плагинов рекомендуется использовать Lucid — интерактивный плагин для просмотра микрокода.
Лифтинг: великий и ужасный#
Базовая идея следующая: необходимо описать работу каждой добавленной инструкции, используя микроинструкции и маппинг (отображения) регистров в микрокод. Иными словами, надо рассказать декомпилятору, что за зверь такой перед ним и с чем его едят. Для этого нам также потребуется обратиться к черновику P Extension, в котором описывается поведение интересующих нас инструкций, и перевести это на язык, понятный конечному инструменту, — тот самый процесс лифтинга.
Вот фрагмент кода класса лифтера с примером самой «зубодробительной» реализации — для инструкций maddr32 и msubr32. Если интересно, то весь код с пояснениями можно найти на Гитхабе.
class PExtensiionLifter(microcode_filter_t):
def __init__(self):
super(PExtensiionLifter, self).__init__()
self._p_ext_handlers = {
PExtension.maddr32: self._maddr32,
PExtension.msubr32: self._msubr32,
PExtension.mulr64: self._mulr64,
PExtension.umar64: self._umar64,
PExtension.mulsr64: self._mulsr64,
}
self._NO_MOP = mop_t()
def install(self):
install_microcode_filter(self, True)
print(f"Installed P-Extension lifter... ({len(self._p_ext_handlers)} instruction(s) supported)")
def remove(self):
install_microcode_filter(self, False)
print("Removed P-Extension lifter...")
def match(self, cdg):
return cdg.insn.itype in self._p_ext_handlers
def apply(self, cdg):
return self._p_ext_handlers[cdg.insn.itype](cdg, cdg.insn)
def _mac_common(self, cdg, insn, op: m_add | m_sub):
rd = reg2mreg(insn.Op1.reg)
rs1 = reg2mreg(insn.Op2.reg)
rs2 = reg2mreg(insn.Op3.reg)
# Временный регистр для промежуточного итога умножения
tmp64 = cdg.mba.alloc_kreg(8) # 64 bits
tmp64_mop = mop_t(tmp64, 8)
# Временный регистр для маскированного результата умножения
tmp32 = cdg.mba.alloc_kreg(8) # 32 bits
tmp32_mop = mop_t(tmp32, 8)
imm_mop = mop_t()
imm_mop.make_number(0xFFFF_FFFF, 8)
# Hex-Rays не поддерживает операнды разного размера, поэтому мы используем расширение до 8 байтов
# Надеемся, что старшие биты регистров rs1 и rs2 нулевые :)
cdg.emit(m_mul, 8, rs1, rs2, tmp64, 0)
# Как и раньше, маскируем младшую часть умножения 64-битной маской 0x0000_0000_FFFF_FFFF
cdg.emit(m_and, imm_mop, tmp64_mop, tmp32_mop)
# На данном этапе нужно уменьшить разрядность данных до 32 бит. Это задается вторым аргументом (4).
cdg.emit(op, 4, rd, tmp32, rd, 0)
# Удаляем временные регистры и освобождаем ресурсы.
cdg.mba.free_kreg(tmp64, 8)
cdg.mba.free_kreg(tmp32, 4)
return MERR_OK
def _maddr32(self, cdg, insn):
return self._mac_common(cdg, insn, m_add)
def _msubr32(self, cdg, insn):
return self._mac_common(cdg, insn, m_sub)Каждое действие в рамках микроопераций подписано в коде, нюансы умножения в методе _mac_common двух 32-битных чисел с 64-битным результатом с точки зрения лифтера и его API также описаны в соответствующих комментариях.
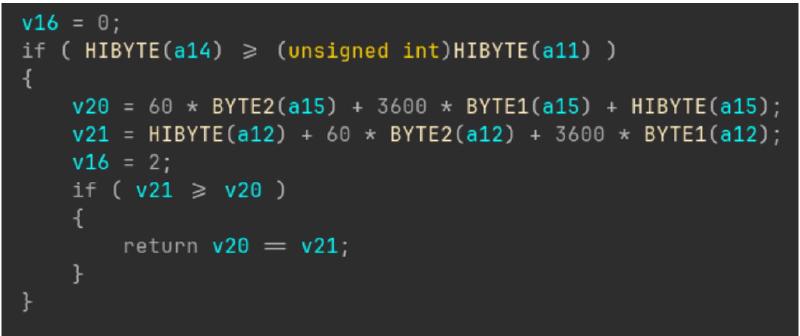
Теперь можем насладиться плодами наших трудов — результат декомпиляции без потерь и ассемблерных вставок представлен ниже:
Заключение#
Если вы не можете проанализировать прошивку, поскольку ваш декомпилятор не имеет поддержки ряда специфических инструкций — это не повод опускать руки. Можно определить, что это за инструкции, написать для них декодер и подружить его с декомпилятором. Не пугайтесь страшных документаций и куце описанных API: нередко за ними стоят весьма стройные концепции, понять и прочувствовать которые удается лишь при непосредственном использовании. А их разработчиков — разве что простить…